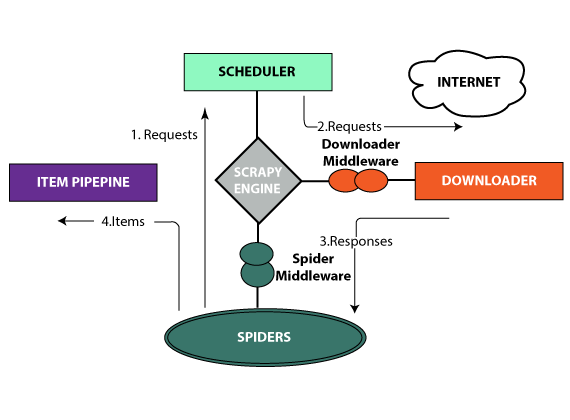
The Working Mechanism of Scrapy
For accomplishing its job, Scrapy utilizes spiders and they are self-contained crawlers which are provided some instructions. You can build them easily in Scrapy when you allow developers to reprocess their code.
We have subject-specific writers and so, students do not face any difficulty in getting assignment slolution from us on any topic. Students who love our features take Scrapy assignment help from us.
Features of Scrapy
Functionality – Scrapy is considered the complete package to download web pages and also process them before saving them in databases and files.
Learning curve – Scrapy is known as the motivation for web scraping. It proposes to people many ways in which they can scrape web pages. People must devote their time to learning and understanding the working mechanism of Scrapy but when they learn it, they can ease the methods of making web crawlers. Additionally, they can also run it from only one line of command. For turning into an expert in Scrapy, you must practice well and also learn every functionality attached to it.
Load and speed – With Scrapy, you can get many jobs accomplished as it is capable of crawling many URLs in only some time.
Extending functionalities – Scrapy proposes item pipelines and they permit people to write functions right in their spider which can process the data, like validate data, remove data, and save data. Again, it proposes spider Contracts too for testing the spiders. Scrapy permits people to form deep crawlers and generic crawlers. It also permits people to manage many variables, like redirection, retries, etc.
Students rely on our work because our assignment providers never make any grammatical errors in our work. Hence, it seems a wise decision on their part to take Scrapy homework help from us.


 3 Bellbridge Dr, Hoppers Crossing, Melbourne VIC 3029
3 Bellbridge Dr, Hoppers Crossing, Melbourne VIC 3029

