The MapReduce programs in cloud compound remain parallel in nature and are highly helpful to perform huge-scale data analysis through multiple machines in a cluster. The significant benefit of MapReduce is that it can easily scale data processing on multiple computing nodes.
It is a programming pattern in the Hadoop framework, which can be used for accessing huge data in an HDFS or Hadoop File System. It is a core part that is integral to the functioning of a Hadoop framework. If you are confused regarding the topic, our online hadoop assignment help tutors shall simply explain the topic.
The Algorithm
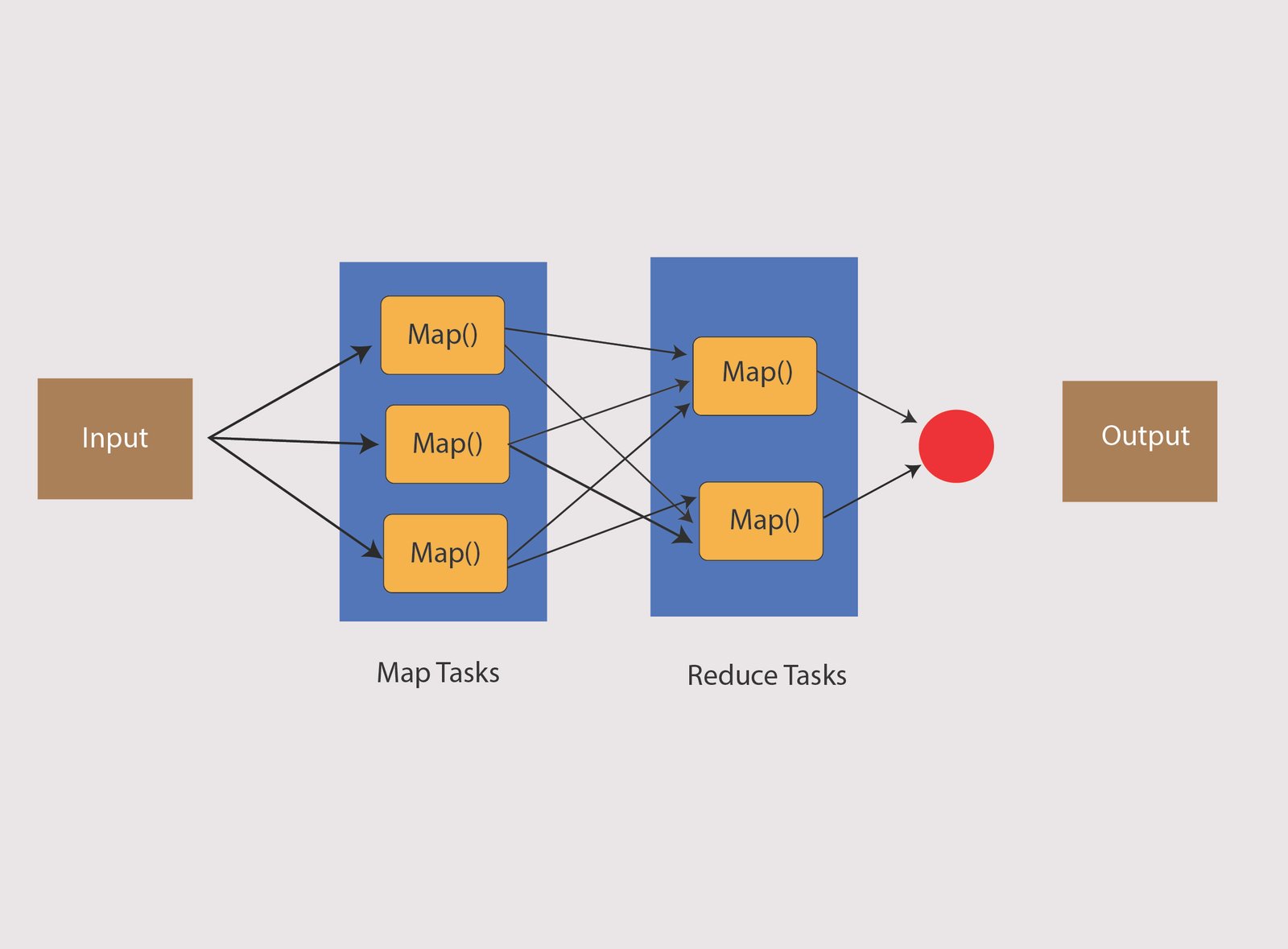
MapReduce program performs in three stages such as map stage, shuffle stage, and reduce stage. These are discussed in our MapReduce assignment help online:
- Map Stage: The job of a mapper is processing the input data. The input data is in the form of directory or file and it is stored in the HDFS. Input is passed to a mapper function by line. A mapper processes the data and builds many small data chunks.
- Reduce Stage: It is the combination of Reduce stage and Shuffle stage. The job of the reducer is processing the data, which comes from a mapper. It gives a new output that shall be stored in an HDFS.
In a MapReduce job, Hadoop sends a Map and reduce jobs to the servers in a cluster. The framework can manage the data-processing details including issuing tasks, copying data in a cluster, and verifying task completion. Many computing happens on nodes along with data on local places that minimize the network traffic.
After completing the given jobs, a cluster gathers and minimizes the data for forming an appropriate result and then sending it to the Hadoop server. We, at BookMyEssay offer urgent MapReduce assignment help online and writing services to our students within a short period.


 3 Bellbridge Dr, Hoppers Crossing, Melbourne VIC 3029
3 Bellbridge Dr, Hoppers Crossing, Melbourne VIC 3029

