The ability of Full-Text search in SQL varies from searching using the predicates like REGEXP, LIKE, and SIMILAR TO, as the matching is not pattern-based but term-based. The string comparison in a Full-Text search uses the normal collation settings regarding a database. The Full-Text search uses international features, which are supported by SQL.
What are the Advantages of Using a Full-Text Search Engine?
Full-text search engines can excel at efficiently and quickly searching huge volumes of text. It might include unstructured data such as a Word document or a semi-structured content such as HTML web pages that have some metadata and structure, however, mostly text.
These engines can categorize the information depending on values in a data (price range, alphabetical, color, region, file type, size, author). The capabilities of the text search are flexible and rich and include support for keyword searching, Boolean operators, Google-style +/-, proximity operations, natural language processing, and other features.
They have relevant ranking abilities for deciding the best match for queries. The calculations look at the frequency of the query terms in a document, the frequency in a corpus, and the proximity to one another, among many other factors.
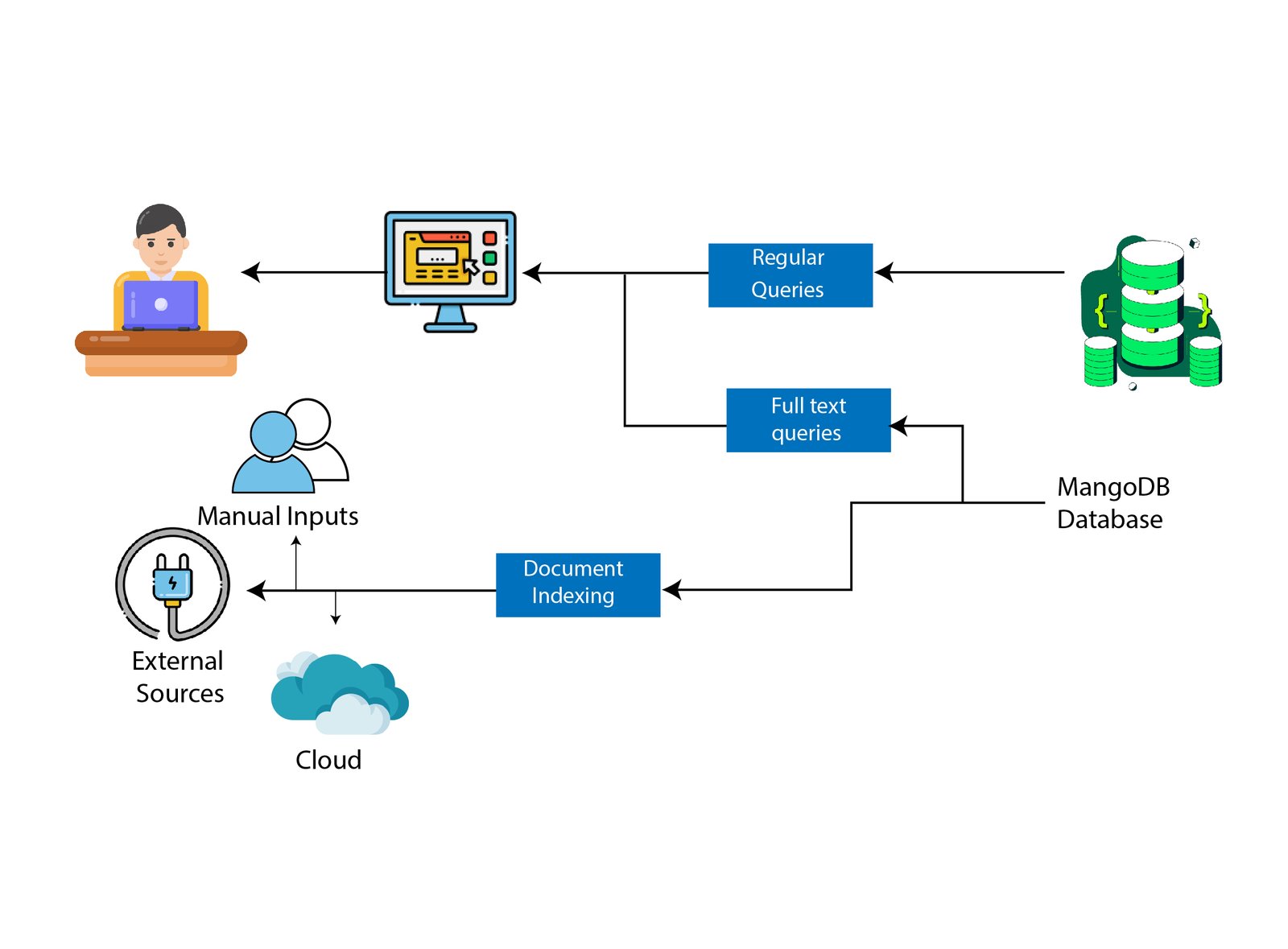
Full-text search engines depend on indexes for performing queries. An inverted index is a common kind of index that counts all terms-numbers, words, etc in all documents giving an indication of the documents that contain the term.
As stated in our Full-Text Search Engines homework help online besides indexing the data, many full-text search engines retrieve and store the data in the original form. It can populate the search results along with actual data from a document thus providing the users a good idea regarding the document before clicking for seeing it. The systems support incremental indexing, and the capability to delete, add or add separate records.
They do not depend completely on the text but can depend on AI models for influencing relevance to the user queries. They can index data from various data sources. It might hold data from web servers, file systems, databases, CRM systems, and other information sources.


 3 Bellbridge Dr, Hoppers Crossing, Melbourne VIC 3029
3 Bellbridge Dr, Hoppers Crossing, Melbourne VIC 3029

